
- ホーム
- >>
- ソフト
- >>
- OCRによる文字認識ソフトの実験
OCRによる文字認識ソフトの実験
文字認識ソフトの認識実験を行いました。文字を入力する作業は時間が掛かります。その作業をサポートしてくれるソフトが文字認識ソフトです。
サポートと言いましたのは、文字の認識率が必ずしも100%ではないからです。私も100%に近づけるために、いろいろな工夫をしています。読みにくい文字、コピーを繰り返して潰れた文字などへの認識率は極めて低いのが現状です。
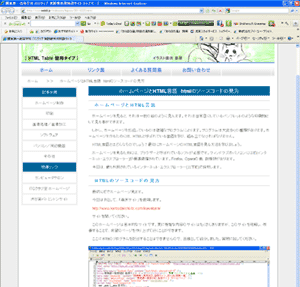
ホームページで使われている文字は、印刷物と比較すると粗い方だと思います。今回は、そのような粗い文字でも認識できるのかを実験してみました。読み取りの対象は、指導員サイトです。
重要なことですが、コンテンツの取り扱いには十分注意してください。他者のコンテンツには著作権が存在しますので、無断で利用すると罰せられます。
自分の書いた記事や論文の印刷物は有るけれど、文字データを紛失してしまった。文字数が多くて入力するのが大変な時。又はコンテンツの権利者から使用許可を頂いたけれど、印刷物だけでデジタルデータが無い。そんな時にサポートしてくれるソフトです。
①印刷物をスキャナーで読み込み、画像データに変換します。
②翻訳をしたい部分を切り出しします。
③文字認識ソフトにセットします。
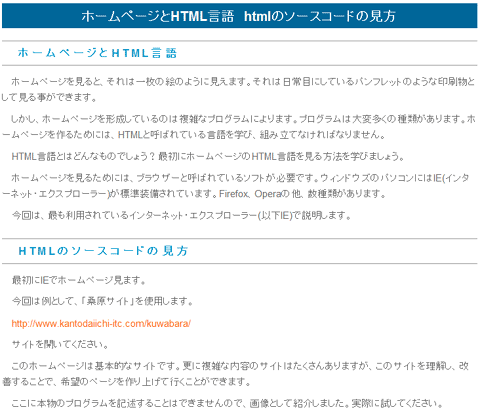
今回は「読み取り革命」というソフトを使用しました。
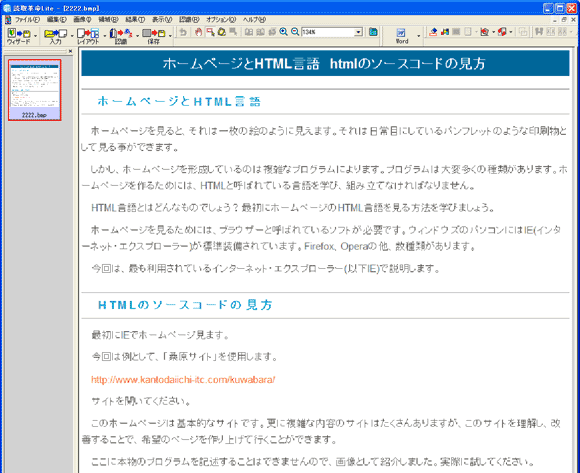
④認識結果
以下が認識結果です。画面の左は、元画像。右は認識後の文字データです。認識に自信が無い部分にグレーの色が文字の上に乗っています。認識は100%ではありませんから、間違いが有るという前提で校正してください。それでも8年前のソフトと比較すると、認識率はとても改善されたと思います。
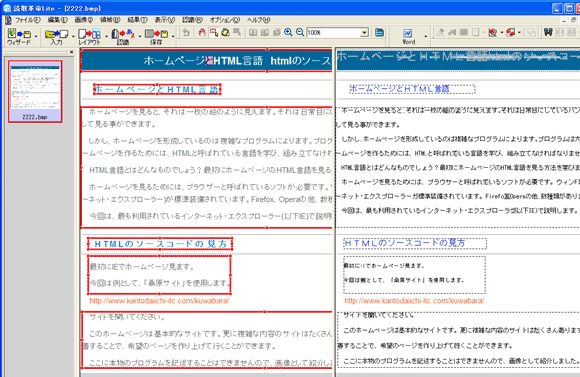
※誤認識部分の拡大です。「x、」が「瓦」に、「)」が「づ」に誤変換されているのが分かります。

